La Gestión de Incidencias tiene como objetivo resolver, de la manera más rápida y eficaz posible, cualquier incidente que cause una interrupción en el servicio.
La Gestión de Incidencias no debe confundirse con la Gestión de Problemas, pues a diferencia de esta última, no se preocupa de encontrar y analizar las causas subyacentes a un determinado incidente sino exclusivamente a restaurar el servicio. Sin embargo, es obvio, que existe una fuerte interrelación entre ambas.
Por otro lado, también es importante diferenciar la Gestión de Incidencias de la Gestión de Peticiones, que se ocupa de las diversas solicitudes que los usuarios plantean para mejorar el servicio, no cuando éste falla.

Interrelaciones: Debe existir una estrecha relación entre la Gestión de Incidencias y otros procesos TI con el objetivo de: Mejorar el servicio y cumplir adecuadamente los SLAs, conocer la capacidad y disponibilidad de la infraestructura y planificar y realizar los cambios necesarios para la optimización y desarrollo del servicio TI.
Monitorización y Seguimiento: Todo el proceso debe ser controlado mediante la: Emisión de informes, actualización de las bases de datos asociadas y monitorización de los niveles de servicio.
Incidencia: Interrupción de los servicios TI, comunicada por usuarios o generada automáticamente por aplicaciones.
Service Desk: Responsable directa de la Gestión de las incidencias, centro de contacto de la organización TI y primera línea de soporte.
Registro y Clasificación: Creación de un registro de incidente: Prioridad = Impacto * Urgencia Categorización: Asignación de tipo y personal de soporte.
Base de Datos de Conocimiento KDB: Análisis y diagnóstico: Consulta BB.DD. Conocimiento, ¿Solución preestablecida?
¿Resuelto? Si se conoce el método de solución: Se asignan los recursos necesarios. Si NO se conoce el método de solución: Se escala la incidencia a un nivel superior de soporte.
Resolución y Cierre: Cuando se ha resuelto el incidente satisfactoriamente: Registro del proceso de solución en el sistema y, si es de aplicación, en la BB.DD. de conocimiento. Si fuera necesario, generar una RFC (petición de cambio) a la Gestión de cambios.
Escalado: Existen dos tipos de escalado en el proceso de resolución de una incidencia: Escalado funcional: Se recurre a técnicos de nivel superior. Escalado jerárquico: Entran en juego más altos responsables de la organización TI.
Los objetivos principales de la Gestión de Incidencias son:
- Detectar cualquier alteración en los servicios TI.
- Registrar y clasificar estas alteraciones.
- Asignar el personal encargado de restaurar el servicio según se define en el SLA correspondiente.
Aunque el concepto de incidencia se asocia naturalmente con cualquier malfuncionamiento de los sistemas de hardware y software, según el libro de Soporte del Servicio de ITIL una incidencia es: “Cualquier evento que no forma parte de la operación estándar de un servicio y que causa, o puede causar, una interrupción o una reducción de calidad del mismo”.
Los principales beneficios de una correcta Gestión de Incidencias incluyen:
- Mejorar la productividad de los usuarios.
- Cumplimiento de los niveles de servicio acordados en el SLA.
- Mayor control de los procesos y monitorización del servicio.
- Optimización de los recursos disponibles.
- Una CMDB más precisa, pues se registran los incidentes en relación con los elementos de configuración.
- Y principalmente: mejora la satisfacción general de clientes y usuarios.
Por otro lado una incorrecta Gestión de Incidencias puede acarrear efectos adversos tales como:
- Reducción de los niveles de servicio.
- Se derrochan valiosos recursos: demasiada gente o gente del nivel inadecuado trabajando concurrentemente en la resolución de la incidencia.
- Se pierde valiosa información sobre las causas y efectos de las incidencias para futuras reestructuraciones y evoluciones.
- Se crean clientes y usuarios insatisfechos por la mala y/o lenta gestión de sus incidencias.
Las principales dificultades a la hora de implementar la Gestión de Incidencias se resumen en:
- No se siguen los procedimientos previstos y se resuelven las incidencias sin registrarlas o se escalan innecesariamente y/o omitiendo los protocolos preestablecidos.
- No existe un margen operativo que permita gestionar los “picos” de incidencias, por lo que éstas no se registran adecuadamente e impiden la correcta operación de los protocolos de clasificación y escalado.

La admisión y registro de la incidencia es el primer y necesario paso para una correcta gestión del mismo. Las incidencias pueden provenir de diversas fuentes tales como usuarios, gestión de aplicaciones, el mismo Centro de Servicios o el soporte técnico, entre otros.
- La admisión a trámite del incidente: el Centro de Servicios debe de ser capaz de evaluar en primera instancia si el servicio requerido se incluye en el SLA del cliente y en caso contrario reenviarlo a una autoridad competente.
- Comprobación de que ese incidente aún no ha sido registrado: es muy habitual que más de un usuario notifique la misma incidencia y por lo tanto han de evitarse duplicaciones innecesarias.
- Asignación de referencia: al incidente se le asignará una referencia que le identificará unívocamente, tanto en los procesos internos como en las comunicaciones con el cliente.
- Registro inicial: se ha de introducir en la base de datos asociada la información básica necesaria para el procesamiento del incidente (hora, descripción del incidente, sistemas afectados…).
- Información de apoyo: se incluirá cualquier información relevante para la resolución del incidente que puede ser solicitada al cliente a través de un formulario específico, o que puede ser obtenida de la propia CMDB (hardware interrelacionado), etc.
- Notificación del incidente: en los casos en que el incidente pueda afectar a otros usuarios, éstos deben ser notificados para que conozcan cómo esta incidencia puede afectar su flujo habitual de trabajo.
El proceso de clasificación debe implementar, al menos, los siguientes pasos:
- Categorización: se asigna una categoría (que puede estar a su vez subdividida en más niveles) dependiendo del tipo de incidente o del grupo de trabajo responsable de su resolución. Se identifican los servicios afectados por el incidente.
- Establecimiento del nivel de prioridad: dependiendo del impacto y la urgencia se determina, según criterios preestablecidos, un nivel de prioridad.
- Asignación de recursos: si el Centro de Servicios no puede resolver el incidente en primera instancia, designará al personal de soporte técnico responsable de su resolución (segundo nivel).
- Monitorización del estado y tiempo de respuesta esperado: se asocia un estado al incidente (por ejemplo: registrado, activo, suspendido, resuelto, cerrado) y se estima el tiempo de resolución del incidente en base al SLA correspondiente y la prioridad.
En primera instancia, se examina el incidente con ayuda de la Base de Conocimiento (KB) para determinar si se puede identificar con alguna incidencia ya resuelta y aplicar el procedimiento asignado.
Si la resolución del incidente se escapa de las posibilidades del Centro de Servicios éste redirecciona el mismo a un nivel superior para su investigación por los expertos asignados. Si estos expertos no son capaces de resolver el incidente, se seguirán los protocolos de escalado predeterminados.
Durante todo el ciclo de vida del incidente se debe actualizar la información almacenada en las correspondientes bases de datos para que los agentes implicados dispongan de información sobre el estado del mismo.
Cuando se haya solucionado el incidente se:
- Confirma con los usuarios la solución satisfactoria del mismo.
- Incorpora el proceso de resolución al SKMS.
- Actualiza la información en la CMDB sobre los elementos de configuración (CIs) implicados en el incidente.
- Cierra el incidente.
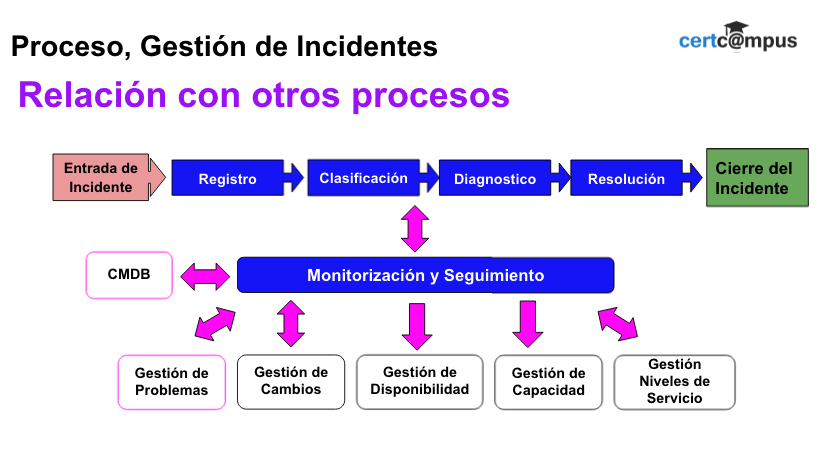
Gestión de Configuraciones: La CMDB juega un papel clave en la resolución de incidentes pues, por ejemplo, nos muestra información sobre los responsables de los componentes de configuración implicados. La CMDB también nos permite conocer todas las implicaciones que pueden tener en otros servicios el mal funcionamiento de un determinado CI (Elemento de Configuración).
Gestión de Problemas: Ofrece ayuda a la Gestión de Incidentes informando sobre errores conocidos y posibles soluciones temporales. Por otro lado establece controles sobre la calidad de la información registrada por la Gestión de Incidentes para que esta sea de utilidad en la detección de problemas y su posible solución.
Gestión de Cambios: La resolución de un incidente puede generar una RFC (petición de cambio) que se envía a la Gestión de Cambios. Por otro lado, un determinado cambio erróneamente implementado puede ser el origen de múltiples incidencias y la Gestión de Cambio debe mantener cumplidamente informada a la Gestión de Incidencias sobre posibles incidencias que los cambios realizados puedan causar en el servicio.
Gestión de Disponibilidad: Utilizará la información registrada sobre la duración, el impacto y el desarrollo temporal de los incidentes para elaborar informes sobre la disponibilidad real del sistema.
Gestión de Capacidad: Se ocupará de incidentes causados por una insuficiente infraestructura TI (insuficiente ancho de banda, capacidad de proceso, etc…)
Gestión de Niveles de Servicio: La Gestión de Incidentes debe tener acceso a los SLA acordados con el cliente para poder determinar el curso de las acciones a adoptar. Por otro lado, la Gestión de Incidentes debe proporcionar periódicamente informes sobre el cumplimiento de los SLAs contratados.
La correcta elaboración de informes forma parte esencial en el proceso de Gestión de Incidencias.
Estos informes deben aportar información esencial para, por ejemplo:
- La Gestión de Niveles de Servicio: es esencial que los clientes dispongan de información puntual sobre los niveles de cumplimiento de los SLAs y que se adopten medidas correctivas en caso de incumplimiento.
- Monitorizar el rendimiento del Centro de Servicios: conocer el grado de satisfacción del cliente por el servicio prestado y supervisar el correcto funcionamiento de la primera línea de soporte y atención al cliente.
- Optimizar la asignación de recursos: los gestores deben conocer si el proceso de escalado ha sido fiel a los protocolos preestablecidos y si se han evitado duplicidades en el proceso de gestión.
- Identificar errores: puede ocurrir que los protocolos especificados no se adecuen a la estructura de la organización o las necesidades del cliente, por lo que se deberán tomar medidas correctivas.
- Disponer de Información Estadística: que puede ser utilizada para hacer proyecciones futuras sobre asignación de recursos, costes asociados al servicio, etc.
Por otro lado una correcta Gestión de Incidencias requiere de una infraestructura que facilite su correcta implementación. Entre ellos cabe destacar:
- Un correcto sistema automatizado de registro de incidentes y relación con los clientes
- Un SKMS que permita comparar nuevos incidentes con incidentes ya registrados y resueltos. Un SKMS actualizado permite:
- Evitar escalados innecesarios.
- Convertir el saber hacer de los técnicos en un activo duradero de la empresa.
- Una CMDB que permita conocer todas las configuraciones actuales y el impacto que éstas puedan tener en la resolución del incidente.